
Todos tendemos a valorar las encuestas según criterios subjetivos, aplaudiendo aquellas que dicen lo que nos gusta y despotricando de aquellas cuyos resultados no nos agradan tanto; es natural. Sin embargo, hay casos flagrantes: encuestadoras que nos presentan sistemáticamente, mes tras mes, resultados disparatados cuando no directamente risibles, que insultan el más elemental sentido común: que hacen sospechar que no estamos ante simple torpeza sino algo ante más grave, como puede ser sesgos deliberados o, directamente, burda manipulación interesada. Pero, ¿es esta presunta manipulación demostrable? ¿Existen criterios objetivos que puedan permitirnos separar el simple error de la mentira? La respuesta es sí; al menos desde el punto de la estadística. Y es que hay encuestas cuyos resultados, como veremos, van en contra de toda probabilidad.
A continuación, y a modo de cuestionario, presentaré algunos conceptos de estadística que debe tener claros cualquiera que quiera analizar una encuesta con un mínimo de criterio y ojo crítico.
¿Qué es el margen de error de una encuesta? ¿Cómo se calcula?
El margen de error es una forma de medir la “fiabilidad” de una encuesta. Y uso comillas porque, en realidad, el asunto es bastante más complejo. Se suele dar en tanto por ciento y se calcula mediante la siguiente fórmula matemática:
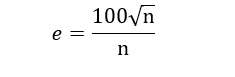
Donde e es el error y n el número de entrevistas. Así, para una encuesta típica de 1200 encuestados, el “error” que aparecería en la ficha técnica sería del 3,2%.
¿Este “error” es el error total, el del partido mayoritario o de cada partido?
NINGUNA de las tres cosas, en realidad. Es un simple parámetro estimativo que se aproxima más o menos al error global. Pero el verdadero error (llamado desviación típica) de la estimación para CADA partido se calcula mediante la siguiente fórmula (derivada de los modelos de distribución binomial)
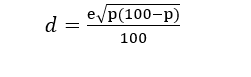
Ejemplo: imaginemos que una encuesta, cuyo supuesto margen de error es del 3%, le da al Partido Urbanita una intención de voto del 20%. Entonces, la desviación típica correspondiente a ese partido sería d= 3*raíz (20*(100-20))/100=1.2%. Es decir, que si la encuesta es veraz y está bien realizada, lo más probable es que este partido acabe sacando entre un 21, 2 y un 18,8%. Cualquier desviación que supere esta horquilla empezará a ser sospechosa.
Entonces, si la desviación típica es de, pongamos ese 1.2%, ¿Significa eso que es imposible que el resultado real acabe yéndose mucho más arriba o debajo de la estimación? Si, por ejemplo, se equivoca en tres puntos, ¿significa que la encuesta está manipulada?
No necesariamente, y ahí está la madre del cordero; es “posible”, pero para nada probable. Seré más concreto:
-La probabilidad de que el error real de una encuesta supere los márgenes de la horquilla fijada por la desviación típica es del 32%
-La probabilidad de que supere una horquilla del doble de la d.t. es de MENOS del 4.2%
-La probabilidad de que supere una horquilla del triple de la d.t. es de UN IRRISODIO 0.2%.
Volvamos a nuestro caso práctico. Imaginemos que las elecciones se celebran a los pocos días, y el Partido Urbanita, para el que se pronosticaba un 20% (y cuyo error o desviación típica era del 1.2%) se queda en un 18.7%. En ese caso el error real sería aproximadamente igual a 1xd (una vez la d.t.) así que podríamos decir que la encuesta está dentro de lo estadísticamente razonable, siendo la probabilidad de este resultado de alrededor del 30%. Imaginemos ahora que el nuestros amigos urbanitas se quedan en un triste 17.5% (2xd): aquí empieza a oler a chamusquina, siendo indicativo de, como mínimo, errores gruesos en “cocina”, pues la probabilidad de esto es de menos del 4% … Pero supongamos ahora que nuestros queridos urbanitas, para colmo de males, se quedan en un 16. 5%, es decir, que el error de la encuesta TRIPLICA a la desviación. Aquí sí que habría que asumir o bien sesgo o bien errores sistemáticos del tamaño de la pirámide de Keops o bien directamente manipulación, pues la probabilidad sería MENOR a una entre 500.
¿Y si este hipotético partido urbanita se hubiera quedado en un 14%, se preguntará alguno maliciosamente? Entonces, la probabilidad de que ese resultado se diera de forma espontanea, y que todo fueran errores aleatorios e “inocentes” sería de una entre 500.000: 8 veces menor a la de ser agraciado por la lotería. Un dato que conviene analizar sin PRISA.
Eso está muy bien, pero en la vida real las elecciones no ocurren inmediatamente, sino que pueden pasar semanas. ¿Cómo podemos saber que hay verdadera mala fe, y no han sido los votantes los que han cambiado repentinamente de opinión? ¿No es eso más natural que imaginar manipulación de los medios o encuestadoras?
Me alegra que me hagas esa pregunta, Relojero. En ese caso, todavía nos quedan algunos cartuchos. El primero es el llamado “intervalo de confianza”, basado en comparar la encuesta “sospechosa” con el PROMEDIO de las encuestas de similares fechas y evaluar su grado de coherencia. Adelanto ya que el Electopromedio NO DEBERÍA admitir ninguna encuesta en la que un partido se desvíe de la media móvil más de un 3%. El otro, que es el que usé para evaluar la fiabilidad de las encuestas pre 20-D es establecer el sesgo, es decir, hasta qué punto las encuestas sobrevaloraron más a una fuerzas o infravaloraron a otras en comparación con su error total acumulado.
Sin embargo, este es tema largo, así que se continuará detallando todo esto en un próximo artículo.
Un artículo de Victorino García.



























































































































































































Tu opinión
Existen unas normas para comentar que si no se cumplen conllevan la expulsión inmediata y permanente de la web.
EM no se responsabiliza de las opiniones de sus usuarios.
¿Quieres apoyarnos? Hazte Patrón y consigue acceso exclusivo a los paneles.